

 Shahrukh Khan
Shahrukh Khan
What is a Data Monetization? | Unlock Revenue with Data Portals
Everyone says, "data is the new gold," and there are a few ways to actually create revenue generation using insights. One such method to unlock the...
Before we get into decision trees, let’s review some basic data-science terminology:
Regression is the concept of modeling the relationship between an outcome variable (let’s say car price) and one or more independent variables (brand, year, color, etc.)
Classification is the concept of classifying a variable into two or more buckets based on its features (Brand: Toyota, Ford, Mazda; Year: 2000-2004, 2005-2010, 2011-2015)
Machine learning is the concept of teaching a computer program to learn and adapt to tasks such as regression or classification without human intervention.
Decision tree-based algorithms are popular machine learning algorithms that are commonly used for problems related to classification or regression. Much like actual trees, decision tree algorithms are based on the structure of a tree. Without further adieu, let’s dive into it.
 What Are Decision Trees?
What Are Decision Trees?It all starts with a question. Let’s say we are trying to make an app that will answer “What’s that animal?”. We’ve collected some data about the characteristics of these animals, such as if the animal has feathers, if it can fly, and its weight.
We are going to use a decision tree algorithm to determine the animal species.
The algorithm thinks in a format similar to the game Twenty Questions. It looks at the data we present it with and determines questions that best separate the data in order to narrow down variables until it reaches the answer. We often present our algorithm with a large amount of data, to “train” the model. This helps the algorithm find key questions to narrow down the appropriate answer. In doing this, when the model is presented with just the data, it’s able to appropriately predict the answer. In the diagram below, you’ll get a visual representation of what it does in a nutshell.
Root nodes are the first question in a decision tree. Internal nodes are the results of the fork or branch that represents decisions (y/n) that spawn from the root node and other internal nodes. Leaf nodes are the outcomes.
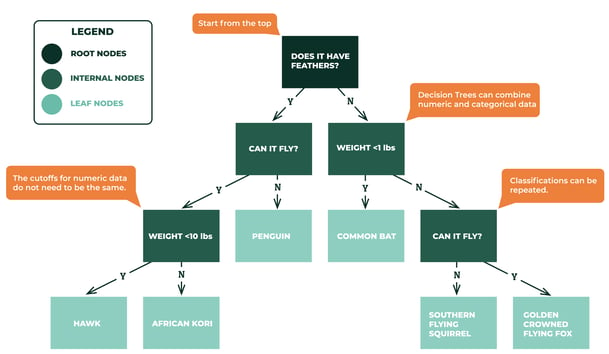
Our algorithm could start by asking itself “Does this animal have feathers? If so, can it fly? If it can fly, does it weigh under 10 pounds?” and so on, until it reaches an outcome.
Note: There are many types of tree-based algorithms. You may hear “random forests” or “adaboost” or “xgboost”. All of these specific algorithms are based on decision tree logic.
Decision trees are fundamentally recursive, meaning the algorithm learns through repetition. The algorithms attempt a bunch of different splits and determine the split that will achieve the correct classification as many times as possible.
To get a little bit more technical, the root node (first question asked) is selected based on the attribute selection measure (ASM) and this is repeated until there is a leaf node (cant be split anymore).
ASM is a technique used in data mining processes for data reduction. The two main ASM techniques are Gini Index and Information Gain (ID3). To dive deeper into these techniques, I’d recommend this blog as a guide.
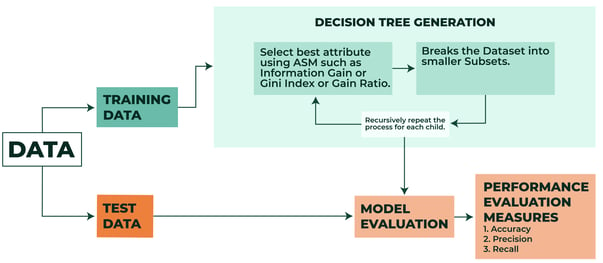
Graphic Reference: Datacamp
Evaluating your tree model boils down to how you evaluate any business decision: Did it work? How well did it work? If it didn’t work, why didn't it work and can we improve it? That said, how would one evaluate the model if it’s about to go into production the first time?
To evaluate your model, analytics teams will typically refer to standard metrics. Commonly used ones are:
Accuracy (%) - If you take what available data you have, and build a tree with 80% of it, how well did you predict the other 20%? If you have 90% accuracy, your tree predicted 9/10 observations correctly for the entire 20% of the data that your tree was not exposed to.
R-squared or Adjusted R-squared (Regression) - How much variation could your independent variables explain in accordance with your outcome variable? The higher the R-squared number, the better. The range of R-squared should be between 0-1 unless there is a mathematical anomaly.
While these are some of the most common, there are other metrics that could tell you how well your model works. These metrics may vary depending on your problem and preference. Other common popular metrics include:
MSE (Common for assessing models related to regression. It assess your predictions)
MAPE (Also common for regression)
True positives / False negatives(Classification)
Precision / Recall (Classification)
ROC Curves / AUC’s(Classification)
Gain / Lift(Classification)
It depends! Decision trees are extremely popular in almost every industry and can tackle any problem you can think of. Below are some examples of decision trees being used in a variety of industries.
As with any algorithms in machine learning, decision tree-based algorithms have their own set of advantages and drawbacks.
Decision trees are easier to build than other algorithms, as they require less effort during data preprocessing.
Normalization / scaling of data is not mandatory for trees.
Missing values are handled better using tree-based algorithms.
Decision trees are very intuitive, and are quite easy to explain and understand.
Depending on changes that may occur in data, the structure of the decision tree can also change, causing instability.
Decision trees often involve a greater time investment to train the model and be computationally taxing.
Decision trees are prone to overfit.
Decision Tree algorithms often aren't the best option for regression-based problems.
Despite the drawbacks, there are always methods of improving your tree algorithm. Efficacy is an art! However, the choice between different algorithms are usually dependent on the business context. Is your project a machine vision project? If so, you generally wouldn't care why it works, you just want it to work. In these cases, neural networks may significantly outperform any other algorithms. However, if you require an algorithm that works well and you can explain with utmost confidence, a tree based algorithm may be your best bet!
Hopefully, this blog gave you valuable insight into what decision tree algorithms are and how they work. Next week, I'll be going over Data Science Applied: Decision Tree's which will be your coding guide to implementing a tree based algorithm! Thank you for reading!

Everyone says, "data is the new gold," and there are a few ways to actually create revenue generation using insights. One such method to unlock the...

Technology has revolutionized how businesses operate, with data being at the forefront of this transformation. The ability to analyze data and...

Why Embedded Analytics with Tableau Embedded analytics is a growing use case for organizations looking to deliver (and even monetize) their data...